Another excellent domestic open source AI video generation model: Step-Video-T2V. The model has 30 billion parameters and can generate high-quality videos with a maximum length of 204 frames. In order to improve computing efficiency and picture quality, the development team specially designed a deep compressed variational autoencoder (Video-VAE), which can compress 16 times in space and 8 times in time, while still maintaining excellent video reconstruction effects.
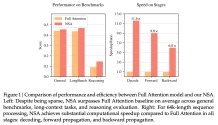
Step-Video supports Chinese and English input, accurately parses the user's text description through a bilingual text encoder, and uses the 3D Full Attention DiT architecture for training, and uses the Flow Matching method for denoising to generate clear and natural pictures. In addition, the development team also introduced video-based direct preference optimization (Video-DPO) to further optimize video quality through human feedback, reduce artifacts, and make the picture smoother and more realistic.
Step-Video supports Chinese and English input, accurately parses the user's text description through a bilingual text encoder, and uses the 3D Full Attention DiT architecture for training, and uses the Flow Matching method for denoising to generate clear and natural pictures. In addition, the development team also introduced video-based direct preference optimization (Video-DPO) to further optimize video quality through human feedback, reduce artifacts, and make the picture smoother and more realistic.
Last edited: