One reason Meta follow the order is that, thanks to the leak of the Claude code, even companies with mediocre LLM can now create a seemingly decent harness. Acquiring Manus for $2 billion was a losing proposition for Meta, and the fact that they can get a refund is actually a good thing.

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Artificial Intelligence thread
- Thread starter 9dashline
- Start date
If it is a compute problem and US models are being capped due to compute while Chinese models aren't, that would transcend irony and enter poetic territory
Excluding mysterious suitcases from Singapore, compute will also be a bottleneck in China at the pace this has been growing
my latest on the AI supply chain concerns with China's export control cutting off access of MLCC suppliers to heavy rare earth metals. How will this affect Rubin deployment?
on US vs China compute question.
Keep in mind that frontier US AI labs have a pretty large compute advantage over China, at least in terms of training cluster compute.
In overall compute, China actually has plenty inside China and outside of China (like with ByteDance, Ali & Tencent in their overseas Data centers). But the problem is that the big tech in China that has large Nvidia clusters are not the most innovative AI shops in China. Whereas Zhipu and Moonshot are probably limited in their Nvidia cluster. Even now, AI researchers in China don't like to use Ascend, they like Cuda.
Now that might be changing since with LLM coding, you can now get kernels for AI chips designed really well (like Qwen did with M890). But there is a gap between when OpenAI and Anthropic got their compute and funding vs when the DeepSeek, Zai and Moonshot got theirs. So that's why you can potentially see a case where American ones just iterate faster. It's unclear to me the implication of that, since the only purpose I've seen in general purpose LLM so far is cyber warfare and replacing software engineers.
But this could become problem. Based on the current pace of development by Ascend (+ other domestic chip options and AI supply chain) and China's willingness to hammer Japan's midstream electronic supply chain, you could see some real shift in compute available to Chinese frontier lab and American ones.
But again, DeepSeek is unlikely to get big gains from Ascend until second half of this year. At which time, it can run more experiments and hopefully speed up releases.
If you look at the release cycles, DS is actually pretty slow. DS4 is structurally the best architecture, but legit under trained. Both GLM-5.2 and Kimi 2.7 are a mile ahead in software engineering work. So, I hope they really speed things up later this year. At least do releases every 2 months consistently, instead of 3 or 4.
Keep in mind that frontier US AI labs have a pretty large compute advantage over China, at least in terms of training cluster compute.
In overall compute, China actually has plenty inside China and outside of China (like with ByteDance, Ali & Tencent in their overseas Data centers). But the problem is that the big tech in China that has large Nvidia clusters are not the most innovative AI shops in China. Whereas Zhipu and Moonshot are probably limited in their Nvidia cluster. Even now, AI researchers in China don't like to use Ascend, they like Cuda.
Now that might be changing since with LLM coding, you can now get kernels for AI chips designed really well (like Qwen did with M890). But there is a gap between when OpenAI and Anthropic got their compute and funding vs when the DeepSeek, Zai and Moonshot got theirs. So that's why you can potentially see a case where American ones just iterate faster. It's unclear to me the implication of that, since the only purpose I've seen in general purpose LLM so far is cyber warfare and replacing software engineers.
But this could become problem. Based on the current pace of development by Ascend (+ other domestic chip options and AI supply chain) and China's willingness to hammer Japan's midstream electronic supply chain, you could see some real shift in compute available to Chinese frontier lab and American ones.
But again, DeepSeek is unlikely to get big gains from Ascend until second half of this year. At which time, it can run more experiments and hopefully speed up releases.
If you look at the release cycles, DS is actually pretty slow. DS4 is structurally the best architecture, but legit under trained. Both GLM-5.2 and Kimi 2.7 are a mile ahead in software engineering work. So, I hope they really speed things up later this year. At least do releases every 2 months consistently, instead of 3 or 4.
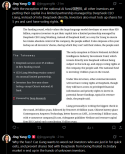
The downstream implications of global perception and popularity on global adoption rates should be interesting to watch.

In addition to the disparity of perceived leadership between US and other countries, there is also a disparity in optimism.

The poll, conducted by U.K.-based research firm Public First surveying over 18,000 people across 15 countries, shows that just over half of American respondents — as well as majorities of people responding in Japan, India and Vietnam — still see the U.S. as the dominant AI superpower. But those in the 11 other countries, including close U.S. allies such as France, Canada and the United Kingdom, see China as the leader. In Germany, only 23 percent of people saw the U.S. as dominant. The polling firm has no connection to Public First Action, a political group backed by the AI company Anthropic.
In addition to the disparity of perceived leadership between US and other countries, there is also a disparity in optimism.
In 2024, 39 percent of U.S. survey participants said AI would make things better for society while 34 percent said it would make things worse. In 2025, this ticked up to 40 percent and 36 percent, respectively. Meanwhile, this year only 31 percent believed AI would make society better, and 40 percent took the opposite outlook. Confidence that AI will improve respondents’ personal lives has fallen sharply from a net positive 15 points in 2024 to just 5 points this year. Prospects for the next generation have deteriorated even further, swinging from a net positive 10 points to a net negative 4 points. This trend is most pronounced among American respondents aged 18 to 24. This group believed that AI was going to improve society by a 4-point margin in 2025. But a year later, that plummeted, with young Americans believing AI would be worse for society by a 13-point margin. Young respondents in the U.K. mirrored these results.
its one of those backhanded compliment articles
DeepSeek has closed their massive round.


Source:
Confirms that DeepSeek is the most ideological of all the Chinese labs, just like Anthropic is in the US. The difference lies in the type of ideology. Anthropic is the most hostile to open source ("safety") and DeepSeek is the most open of all labs.
Both probably have the highest talent density in their respective country.
Source:
Confirms that DeepSeek is the most ideological of all the Chinese labs, just like Anthropic is in the US. The difference lies in the type of ideology. Anthropic is the most hostile to open source ("safety") and DeepSeek is the most open of all labs.
Both probably have the highest talent density in their respective country.
Attachments
-
 1.png385.6 KB · Views: 17
1.png385.6 KB · Views: 17
why is VN number like that tho? how do they cover AI news there?The downstream implications of global perception and popularity on global adoption rates should be interesting to watch.
View attachment 176653
In addition to the disparity of perceived leadership between US and other countries, there is also a disparity in optimism.
View attachment 176654
GLM-5.2 looks like a really good model. I mean I've already picked Kimi for its news research stuff, but it looks like in terms of engineering, GLM-5.2 is the best Chinese model ever in terms of closeness to frontier US models.
This wont be good for Anthropic and OpenAI IPOs
GLM-5.2 looks like a really good model. I mean I've already picked Kimi for its news research stuff, but it looks like in terms of engineering, GLM-5.2 is the best Chinese model ever in terms of closeness to frontier US models.